- DBI Architecture
- DBI Usage
- Example Using DBI
- Installing DBI
- Generic database interface
- Any SQL compatible database can be used with DBI by writing an
appropriate driver
- Many drivers available (e.g. Oracle, MySQL, CSV)
- DBI is a layer of "glue" between an application and one or more
database drivers
- The drivers do the real work
- DBI provides a standard interface and framework for the drivers
to work in
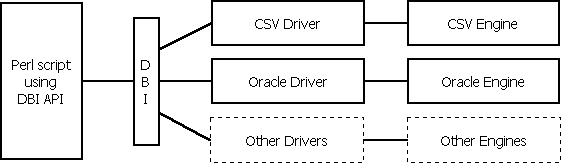
- All database requests are funnelled through DBI
- Drivers implement the methods defined in the DBI API (e.g. connect),
but in a database-specific way
- A common API allows one driver to be plugged in for another (as long
as no special features were used)
- Driver names preceded with "DBD" (database driver), followed by the
driver type (e.g. DBD::CSV)
- Handles are objects returned by various DBI methods
- Can be used to access data at various layers of abstraction
- The handles used by DBI are shown in the figure
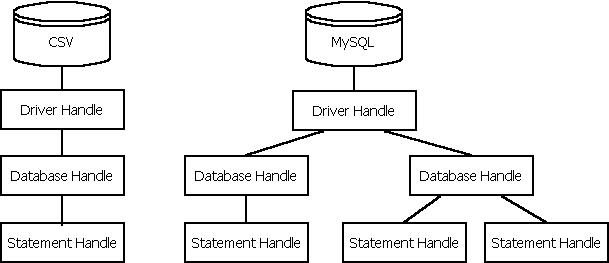
- Driver handle
- A driver handle points at a database type
- If you are connecting
simply to a MySQL database, you should only ever have one driver handle
- If you are connecting to an Oracle and a MySQL database, you will have
two driver handles
- Database handle
- A database handle encapsulates a single connection to a given
database via a driver handle
- There can be >1 database handles per driver handle
- For example, if a script copies data from one database to another of the
same type, then we will have 1 driver handle, and 2 database handles
- Statment handle
- A statement handle encapsulates a statement issued to a database via
a database handle
- Again, there can be any number of statement handles per database handle
- For example, we might need to copy data from one table to another, and
will use 2 statement handles
- Here we will use the DBD::CSV driver
- It represents database tables as comma separated values in a text file
(commonly used to export/import data)
lastName,firstName,phone,department,location
Allen,Woody,2345,Accounting,4-J8
Keaton,Dianne,3456,Marketing,2-A6
- Maps SQL queries to accesses to a CSV file
- To replace CSV database with a more powerful database engine, all you need
to do is to plug in another driver
- We don't need to set up a special database engine
- Creating a database handle
- Creating and dropping tables
- Inserting and modifying data
- Parameters
- Querying the database
- You can create tables by passing a CREATE TABLE command to the do()
method
$dbh->do(qq`
CREATE TABLE address (
name CHAR(20),
location CHAR(30),
age INTEGER
)`);
- To deleted the table use the DROP TABLE command
$dbh->do("DROP TABLE address");
- The following example inserts some data in a table
$dbh->do(qq`
INSERT INTO address (name, location, age)
VALUES ('Bob', 'Ottawa', 33)`);
- An update can be issued in the same way
$dbh->do(qq`
UPDATE address
SET age = age + 1
WHERE name = 'Alice'
AND location = 'Toronto'
`);
- To create the above statements we can use interpolation
$dbh->do(qq`
INSERT INTO address (name, location, age)
VALUES ('$name', '$location', $age)`);
- But in doing so, we need to watch for special characters (e.g.
quotation marks) with meaning in SQL
- A better alternative is to use parameters
$dbh->do(qq`
INSERT INTO address (name, location, age)
VALUES (?, ?, ?)`,
undef, $name, $location, $age);
- Parameter positions are represented by a "?"
- Since the do() method does not return results, it is unsuitable
for SELECT queries
- Querying the database involves several steps
- Prepare the query statement for later execution
- Execute the query
- Fetch the result(s) from the result set
- Clean up the query statement
- Thus a typical method call sequence is:
prepare,
execute, fetch, fetch, ...
execute, fetch, fetch, ...
execute, fetch, fetch, ...
finish
- Even for non-SELECT statements, separating the preparation and execution
of a statement can prove useful
- There are definite advantages for debugging code
- Prepared statements with parameters will also execute more efficiently than
statements that aren't
$sth = $dbh->prepare(qq`
INSERT INTO address (name, location, age)
VALUES (?, ?, ?)`);
while(<CSV>) {
chop;
my ($name,$location,$age) = split /,/;
$sth->execute($name, $location, $age);
}
use DBI;
my $db = DBI->connect("DBI:CSV:f_dir=data/address_book") ||
die("cannot connect: " . $DBI::errstr());
my $query = <<END_OF_QUERY;
CREATE TABLE address (
lastName CHAR(20),
firstName CHAR(20),
phone CHAR(15),
department CHAR(35),
location CHAR(15)
)
END_OF_QUERY
my $stmt = $db->prepare($query) ||
die("cannot prepare: " . $db->errstr());
$stmt->execute() ||
die("cannot execute: " . $db->errstr());
$stmt->finish();
$db->disconnect;
- There are different ways to install the DBI module:
- As a local install on your account
- As a system-wide install (only admin can do that)
- Once you have decided where you will install the
module, you can go about it in two ways:
- Install the module manually
- Use the the Perl Package Manager (PPM)
- A manual install of a Perl module frequently involves using
the Unix make utility
- Make executes instructions in a "make" file for building
a target system
- Make can be invoked with a target, otherwise the first target
in the make file is built
- A make file defines rules which component of the system
depends on which others
- Components are created (e.g. compiled) in the order of
dependency
- The ActivePerl distribution includes a handy tool, the Perl
Package Manager, which automates most of these steps
- PPM retrieves the modules from a package repository, which
contains most common CPAN modules
- For the assignment, we will ask you to use the manual method to
install the modules locally
- First, download the following modules from CPAN
1> DBI
2> SQL::Statement
3> Text::CSV_XS
4> DBD::CSV
- Second, expand each downloaded archive into a directory and execute
the first two installation steps in this directory
1> perl Makefile.PL
2> make
- The localy installed modules can now be accessed using the "blib"
module
- Add the following code to the beginning of your scripts
use blib 'DBI';
use blib 'SQL-Statement';
use blib 'Text-CSV_XS';
use blib 'DBD-CSV';
use blib 'DBI';
use blib 'SQL-Statement';
use blib 'Text-CSV_XS';
use blib 'DBD-CSV';
use DBI;
my $db = DBI->connect("DBI:CSV:f_dir=data/address_book") ||
die("cannot connect: " . $DBI::errstr());
my $query = <<END_OF_QUERY;
CREATE TABLE address (
lastName CHAR(20),
firstName CHAR(20),
phone CHAR(15),
department CHAR(35),
location CHAR(15)
)
END_OF_QUERY
my $stmt = $db->prepare($query) ||
die("cannot prepare: " . $db->errstr());
$stmt->execute() ||
die("cannot execute: " . $db->errstr());
$stmt->finish();
$db->disconnect;
- Here is the detailed procedure for installing the DBI module (the
others install in the same way)
- Change to the directory for the assignment, e.g.
> cd ~/user/course_html/205/a3
- Download the latest release of the module from CPAN
http://search.cpan.org/search?module=DBI
- Extract the installation files from the archive
> gunzip DBI-1.14.tar.gz
> tar xfv DBI-1.14.tar
- Change to the directory with the installation files
> cd DBI-1.14
- Run the first two steps of the installation procedure
> perl Makefile.PL
> make
- Expect to get a warning that certain optional modules are not
installed, but we don't need them
- As a result you will find a new subdirectory "blib" that contains
all files needed to use the module
> ls -R blib
blib:
arch lib man1 man3 script
...
- Optionally you can check that the module has been correctly installed
> make test
- Finally, you need to rename the DBI directory to a name without the version
information
> mv DBI-1.14 DBI
- The archive file can now be deleted